 こんにちは、GreenSnapでiOSエンジニアをやっている山野です。
この記事は、弊社で社内の非エンジニアにも使ってもらえるようなBIツールを探しているときに候補に上がったAWSのQuickSightを調査するにあたって、どうせ色々触ってみるなら、自分の好きなものを対象にしてみたいなと思い、最近のマイブームであるサウナをテーマにして、QuickSightで遊んでみたというネタ記事です。
可視化するデータは、「サウナイキタイ」というポータルサイトを利用します。
こんにちは、GreenSnapでiOSエンジニアをやっている山野です。
この記事は、弊社で社内の非エンジニアにも使ってもらえるようなBIツールを探しているときに候補に上がったAWSのQuickSightを調査するにあたって、どうせ色々触ってみるなら、自分の好きなものを対象にしてみたいなと思い、最近のマイブームであるサウナをテーマにして、QuickSightで遊んでみたというネタ記事です。
可視化するデータは、「サウナイキタイ」というポータルサイトを利用します。
サウナイキタイとは
サウナイキタイとは、サウナ好きなら一度は見たことはあるであろう、国内最大規模のサウナのポータルサイトです。サウナにとって重要な指標である、サウナの温度、水風呂の温度などの基本情報から、アメニティなどの細かい情報までまとまっており、サイト内の独自の指標「イキタイ」により、サウナの人気度合いがわかったり、「サ活」でみんなのサウナ日記を見ることもできる神サイトです。
基本方針
今回、サウナ分析をするにあたり、以下の方針で進めていきます。
- Pythonによるスクレイピングにより、サウナ情報を取得
- AWS QuickSightを使って可視化
Step.1 Pythonによるスクレイピングにより、サウナ情報を取得
環境構築が面倒なので、Google Colaboratory を使い、Pythonによるスクレイピングをします。 (可視化だけ見たい方は読み飛ばしてください。)
ソースコード
# 必要なライブラリのインポート import requests from bs4 import BeautifulSoup import os import pandas as pd # import geocoder # はじめに、ベースとなる1ページ目のURLを定義する base_url = "https://sauna-ikitai.com/search?conditions%5B%5D=target_gender%23is_male_available&ordering=ikitai_counts_desc&prefecture%5B%5D=tokyo&target_gender%5B%5D=male&water_baths__temperature%5Bmin%5D=0" # データ格納用のデータフレーム df = pd.DataFrame()
# スクレイピング対象の URL にリクエストを送り HTML を取得する response = requests.get(base_url) # BeautifulSoupによるHTMLのパース処理 soup = BeautifulSoup(response.text, "lxml") # ページ数を取得 result_number = int(soup.find_all('p', {'class': 'p-result_number'})[0].find_all('span')[0].string) row = 0 sauna_links = [] item_num = 20 page_num = int(result_number / item_num) mod = result_number % item_num if mod != 0: page_num += 1 for p in range(page_num): # スクレイピング対象の URL にリクエストを送り HTML を取得する response = requests.get(base_url + "&page=" + str(p+1)) # BeautifulSoupによるHTMLのパース処理 soup = BeautifulSoup(response.text, "lxml") # class が p-saunaList の div 要素を全て取得する sauna_list_elms = soup.find_all('div', {'class': 'p-saunaList'})[0] # ページ内リンクを取得 sauna_links += [url.get('href') for url in sauna_list_elms.find_all('a')] print(str(p+1) + "ページ / " + str(page_num) + "ページ")
# サウナ名から緯度経度を取得する2 def get_lat_lon_from_address(address): geo_link = "http://geocode.csis.u-tokyo.ac.jp/cgi-bin/simple_geocode.cgi?charset=UTF8&addr=" + address address_response = requests.get(geo_link) # BeautifulSoupによるHTMLのパース処理 address_soup = BeautifulSoup(address_response.text, "lxml") lat = address_soup.find_all('latitude')[0].string lng = address_soup.find_all('longitude')[0].string latlng = {"lat": lat, "lng": lng} return latlng
import re # 住所を分割し、市区町村を取得 def get_municipalities(address): matches = re.match(r'(...??[都道府県])((?:旭川|伊達|石狩|盛岡|奥州|田村|南相馬|那須塩原|東村山|武蔵村山|羽村|十日町|上越|富山|野々市|大町|蒲郡|四日市|姫路|大和郡山|廿日市|下松|岩国|田川|大村)市|.+?郡(?:玉村|大町|.+?)[町村]|.+?市.+?区|.+?[市区町村])(.+)' , address) return matches[2]
def isfloat(s): # 浮動小数点数値を表しているかどうかを判定 try: float(s) # 文字列を実際にfloat関数で変換してみる except ValueError: return False else: return True
# 男、女、共用のどのタイプにデータがあるかを見て、どれを取得するか判断 def getSpecSoup(soup): tmp = soup.find_all('div', {'class': 'p-saunaSpec'}) for item in tmp: elms = item.find('div', {'class': 'p-saunaSpecNot'}) if elms == None: return item
# 温度、収容人数を取得、なければ-を返す def getSpecNumber(p): return p.text.split("\n")[1] if len(p.text.split("\n")) > 1 else "-"
# 値を0,1変換する def replace(str): return str.replace("有り", "1").replace("○", "1").replace("無し", "0").replace("-", "0") # specでimgがあれば変換 def getSpecItems(td): return replace(td.find("img").get("alt")) if td.find("img") != None else "0"
# sauna_linkにサウナ施設のURLを渡すとデータフレームにサウナ情報が追加される # rowはデータフレームの行 def setSaunaInfoToDataFrame(sauna_link, row): # スクレイピング対象の URL にリクエストを送り HTML を取得する sauna_response = requests.get(sauna_link) # BeautifulSoupによるHTMLのパース処理 sauna_soup = BeautifulSoup(sauna_response.text, "lxml") # class が p-saunaDetailShop_info の div 要素を取得する sauna_list_elms = sauna_soup.find_all('div', {'class': 'p-saunaDetailShop_info'})[0] # サウナ情報を取得する sauna_infos_keys = [str(td.string) for td in sauna_list_elms.find_all('th', {'class': 'c-table_th'})] sauna_infos_values = [str(td.string).replace("\n", "").replace(" ", "").replace("\r", " ") for td in sauna_list_elms.find_all('td', {'class': 'c-table_td'})] # イキタイを取得してkey,valueに追加 ikitai_elms = sauna_soup.find_all('div', {'class': 'p-action_number'})[0] sauna_infos_keys.append("イキタイ") sauna_infos_values.append(int(ikitai_elms.string)) # 緯度経度を取得する address = sauna_infos_values[2] latlon = get_lat_lon_from_address(address) sauna_infos_keys.append("緯度") sauna_infos_keys.append("経度") sauna_infos_values.append(latlon["lat"]) sauna_infos_values.append(latlon["lng"]) # 市区町村を取得 municipalities = get_municipalities(address) sauna_infos_keys.append("市区町村") sauna_infos_values.append(municipalities) # 男、女、共用のどのタイプにデータがあるかを見て、どれを取得するか判断 sauna_spec_soup = getSpecSoup(sauna_soup) sauna_spec_elms = sauna_spec_soup.find_all('div', {'class': 'p-saunaSpec_main'})[0] # サウナと水風呂の温度、収容人数など取得 tmp_people = [getSpecNumber(p) for p in sauna_spec_elms.find_all('p', {'class': 'p-saunaSpecItem_people'})[0:2]] tmp_temp = [getSpecNumber(p) for p in sauna_spec_elms.find_all('p', {'class': 'p-saunaSpecItem_number'})[0:2]] # tmp_peopleがまれにない場合があるので適当に追加 tmp_people += ["-", "-"] # floatに変換できるかどうか判定し、できない場合は"-"を格納 sauna_people_vals = [float(item) if isfloat(item) else "-" for item in tmp_people] sauna_temperature_vals = [float(item) if isfloat(item) else "-" for item in tmp_temp] sauna_infos_keys.append("サウナ収容人数") sauna_infos_values.append(sauna_people_vals[0]) sauna_infos_keys.append("水風呂収容人数") sauna_infos_values.append(sauna_people_vals[1]) sauna_infos_keys.append("サウナ温度") sauna_infos_values.append(sauna_temperature_vals[0]) sauna_infos_keys.append("水風呂温度") sauna_infos_values.append(sauna_temperature_vals[1]) # その他情報を取得 spec_elms = sauna_spec_soup.find_all('table', {'class': 'p-saunaSpecTable'})[0] spec_keys = [div.text for div in spec_elms.find_all('div', {'class': 'p-saunaSpecTable_name'})] spec_values = [getSpecItems(td) for td in spec_elms.find_all('td', {'class': 'p-saunaSpecTable_mark'})] sauna_infos_keys += spec_keys sauna_infos_values += spec_values # さらに細かい情報を取得 other_spec_elms = sauna_soup.find_all('div', {'class': 'p-saunaSpecDetail'})[0] other_spec_keys = [span.text for span in other_spec_elms.find_all('span', {'class': 'p-saunaSpecList_key'})] other_spec_values = [replace(span.text) for span in other_spec_elms.find_all('span', {'class': 'p-saunaSpecList_value'})] sauna_infos_keys += other_spec_keys sauna_infos_values += other_spec_values # サウナ情報をデータフレームに入れる for index, sauna_info in enumerate(sauna_infos_values): key = sauna_infos_keys[index] if sauna_info == "" or sauna_info == "None": sauna_info = "-" df.loc[row, key] = sauna_info
start_index = 0 for row, sauna_link in enumerate(sauna_links[start_index:]): print(sauna_link) setSaunaInfoToDataFrame(sauna_link, row + start_index) print(str(row + start_index + 1) + " / " + str(result_number))
# 空欄を0埋め df.fillna(0, inplace=True) # csv出力 df.to_csv('sauna.csv', index=False)
上記コードを上から順に実行することで、最終的にsauna.csvというcsvファイルが生成されます。 ソースコードはGitHubにも上げているので参考にしてください。
Step.2 AWS QuickSightによる可視化
いよいよ、QuickSightの出番です。 QuickSightは初見では少しわかりづらいですので、順を追って解説します。
1. データセットのインポート
Step.1で作成したsauna.csv というファイルをQuickSightのデータセットとしてアップロードします。
QuickSightのメニューから、データセットを選択し、右上の「新しいデータセット」をクリックします。
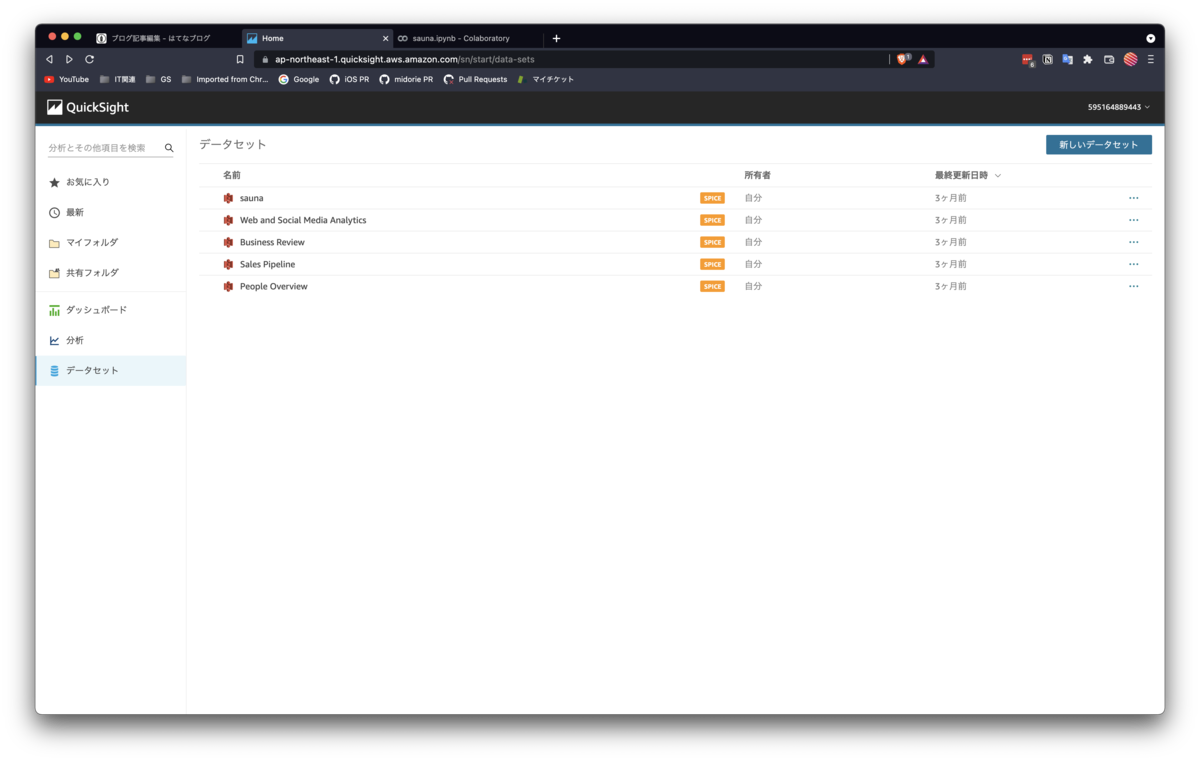
すると、データセットとして選択できるものの一覧が表示されます。
今回はcsvを直接アップロードするので、「ファイルのアップロード」を選択します。
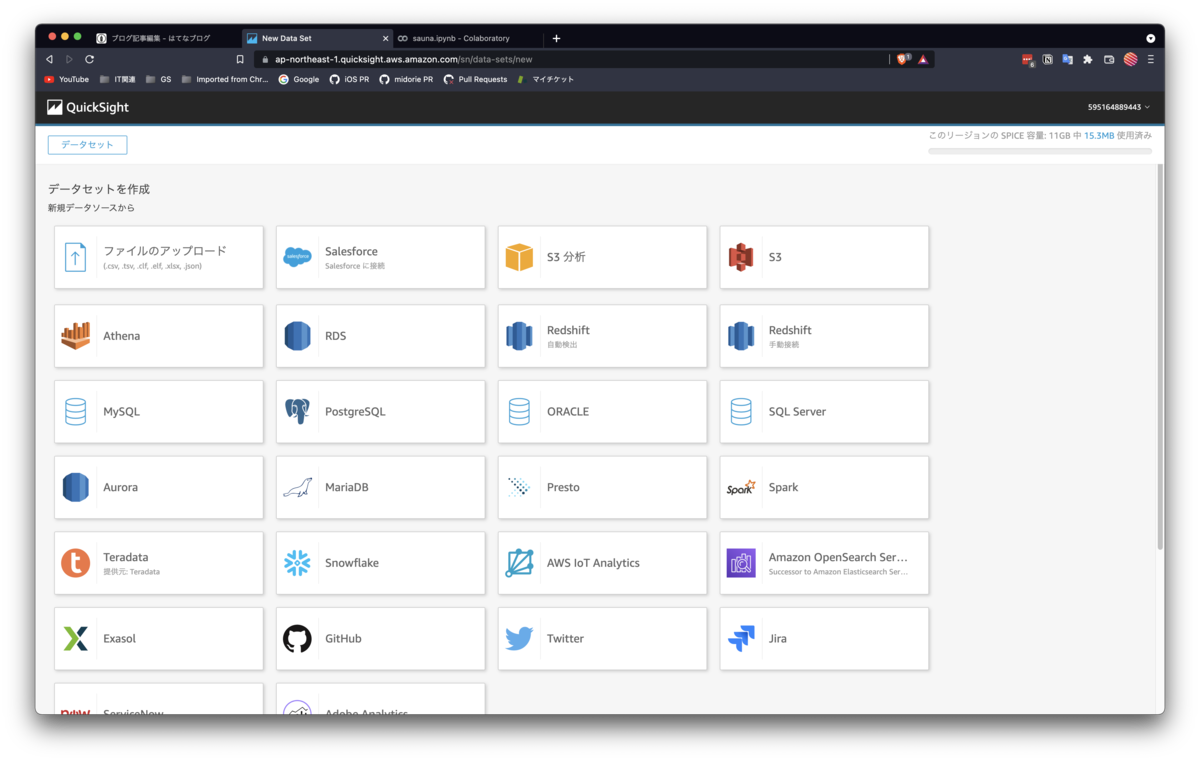
Step.1で作成したsauna.csvをアップロードします。
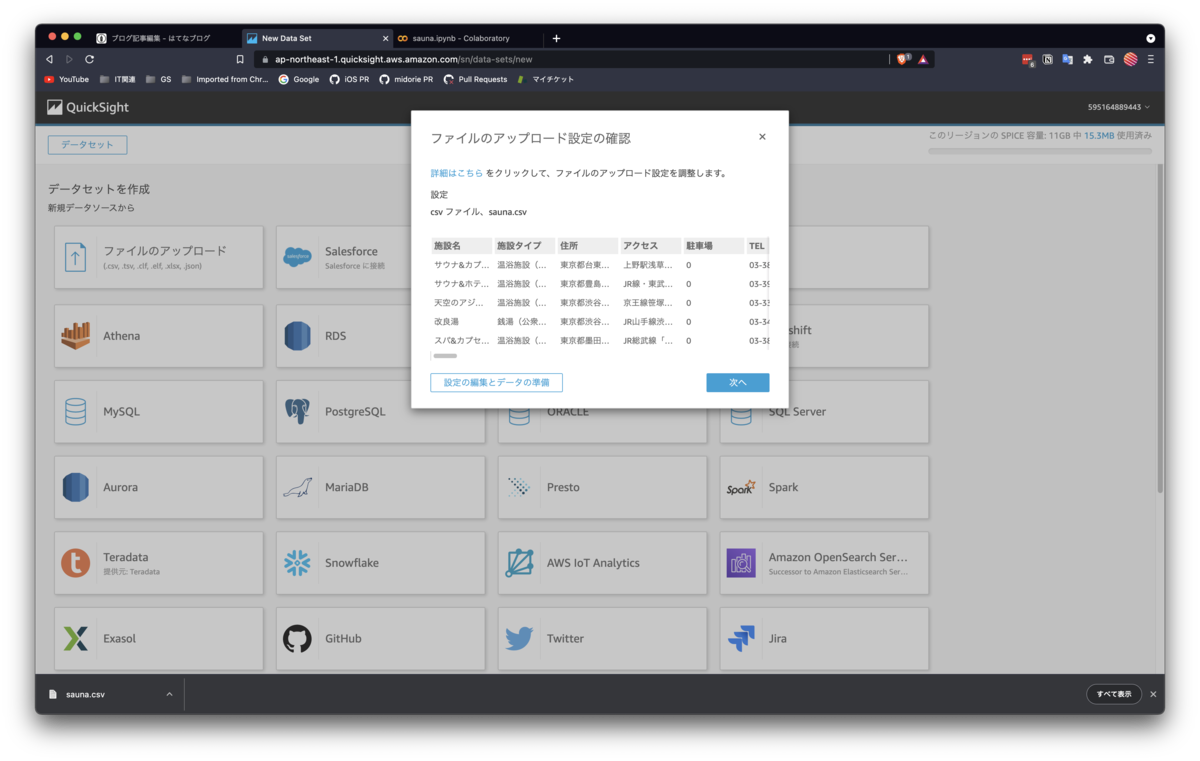
2. データセットの編集
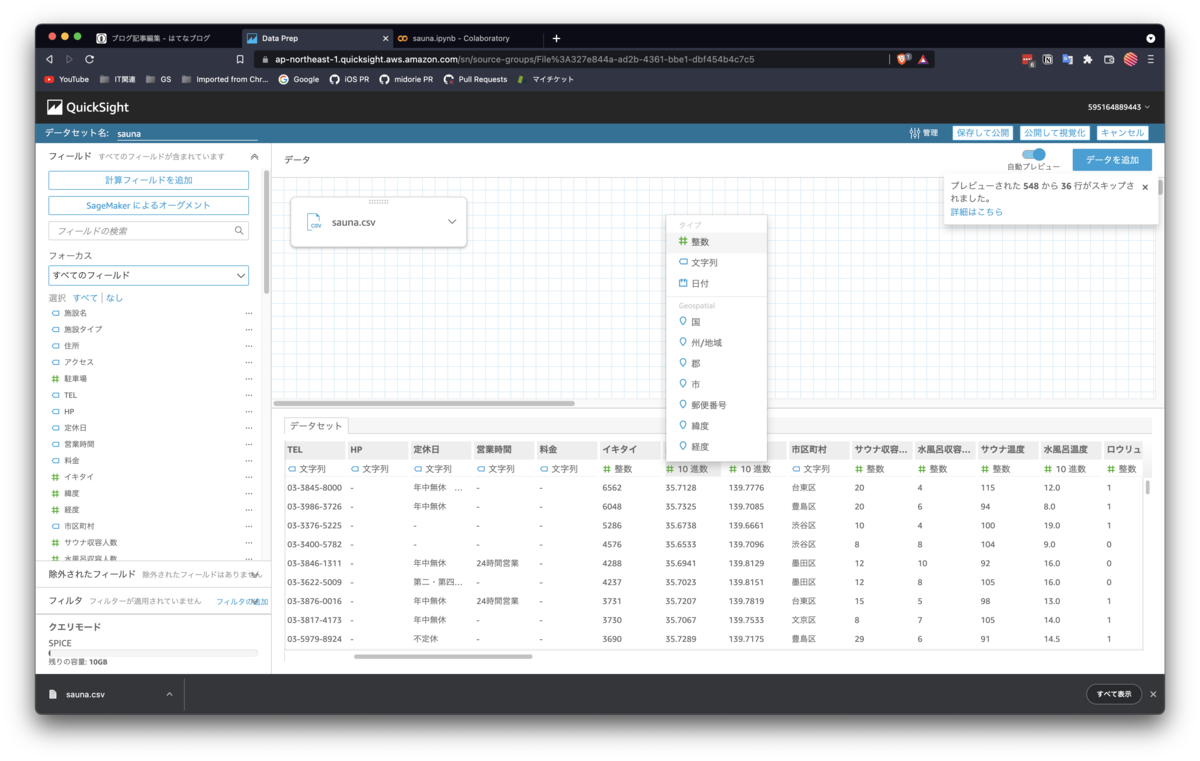
3. データの可視化(基本編)
いよいよ可視化に移ります。
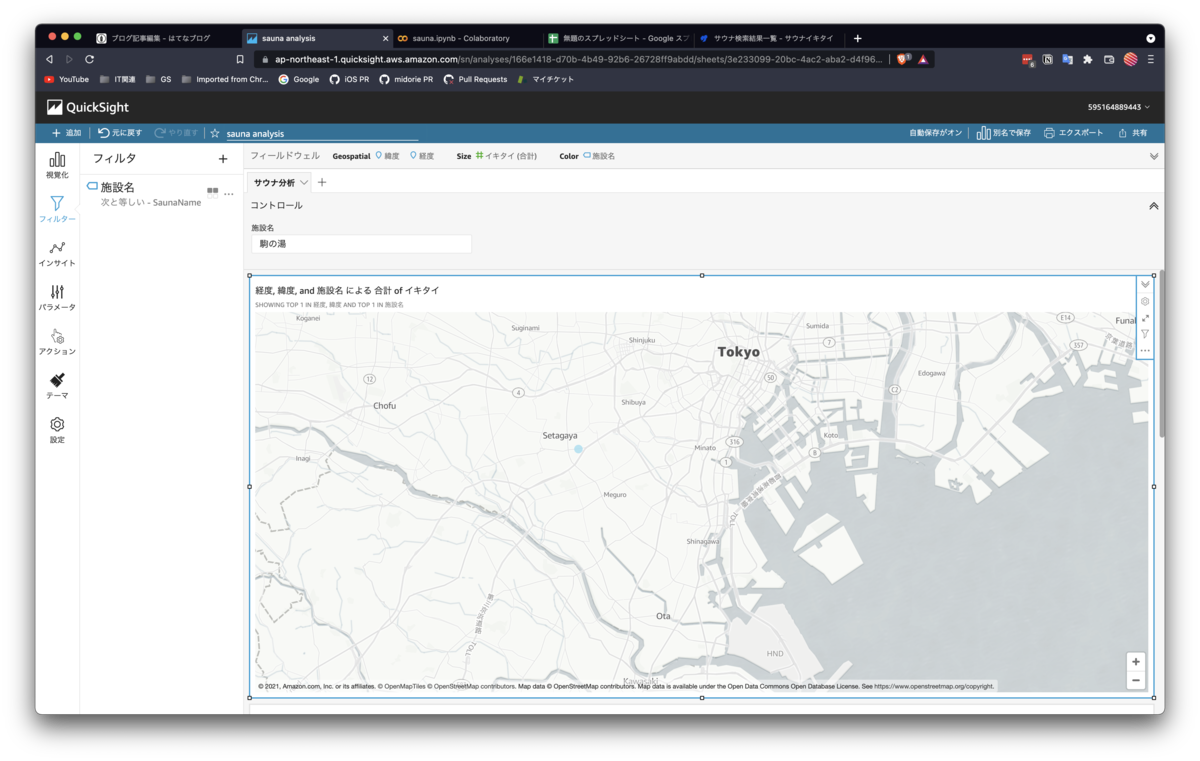
まずは、サウナイキタイにおける人気度をあらわす「イキタイ」数を地図上にマッピングしてみます。
まずは、左下のビジュアルタイプから、「地図上のポイント」を選択します。
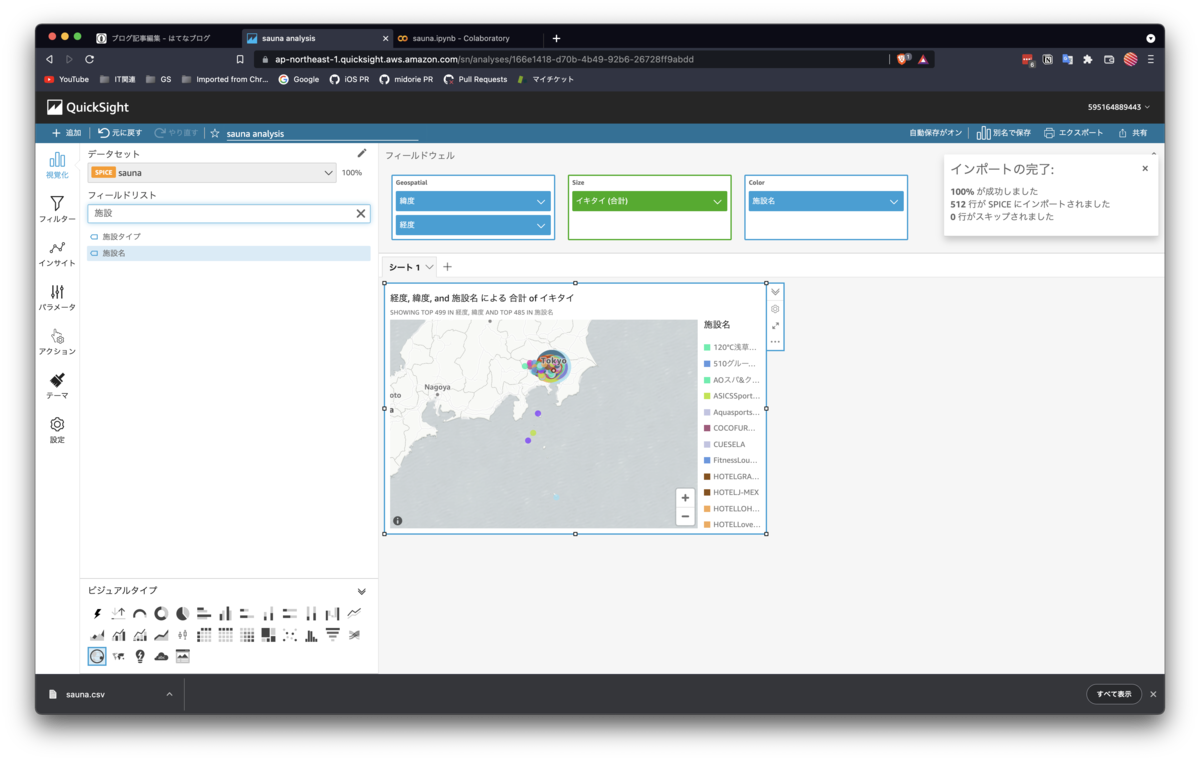
次に、左のフィールドリストから、緯度、経度を探し、画面上部のフィールドウェルの中の、Geospatial内へドラッグアンドドロップします。
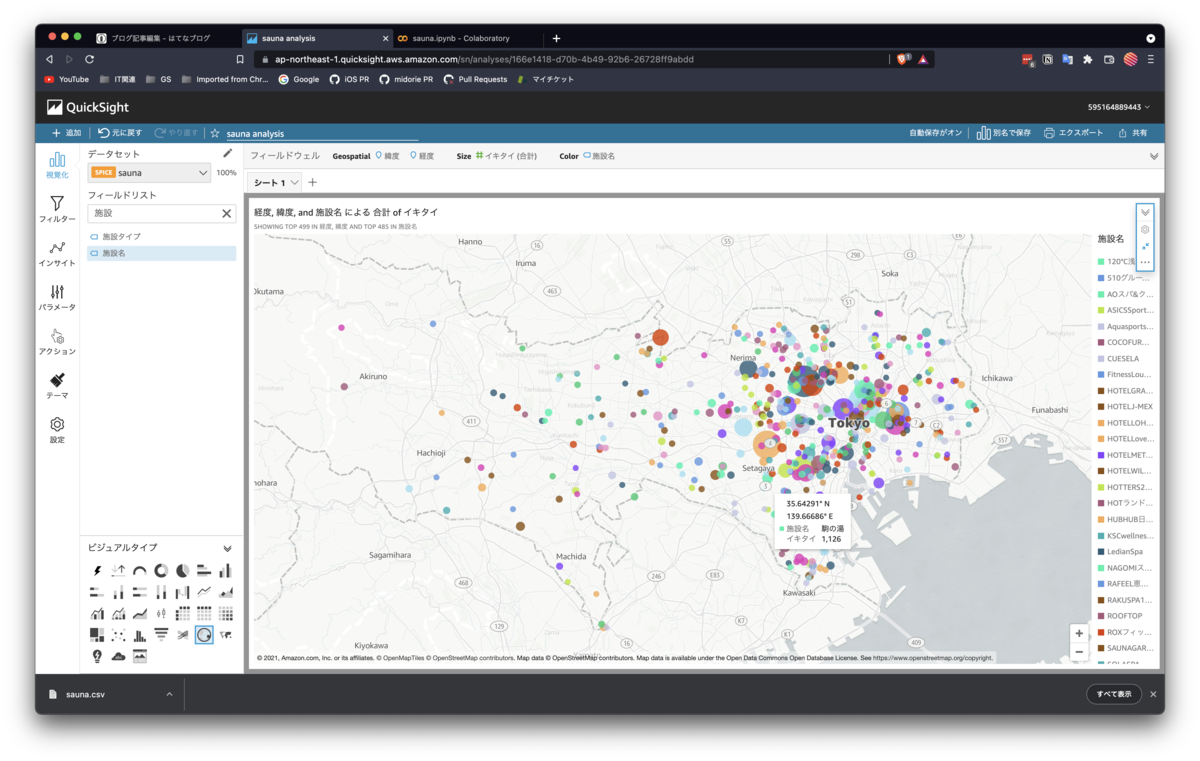
さらに、Sizeにイキタイ(合計)、Colorに施設名をドラッグアンドドロップします。
するとこのように、地図上にイキタイ数に応じて円のサイズが違うものが地図上にマッピングされます。

他にも、いろんなビジュアルタイプがあるので、手当り次第触ってみるのがいいかと思います。たとえば、サウナと水風呂の温度を散布図を使ってマッピングすると、

4. データの可視化(応用編)
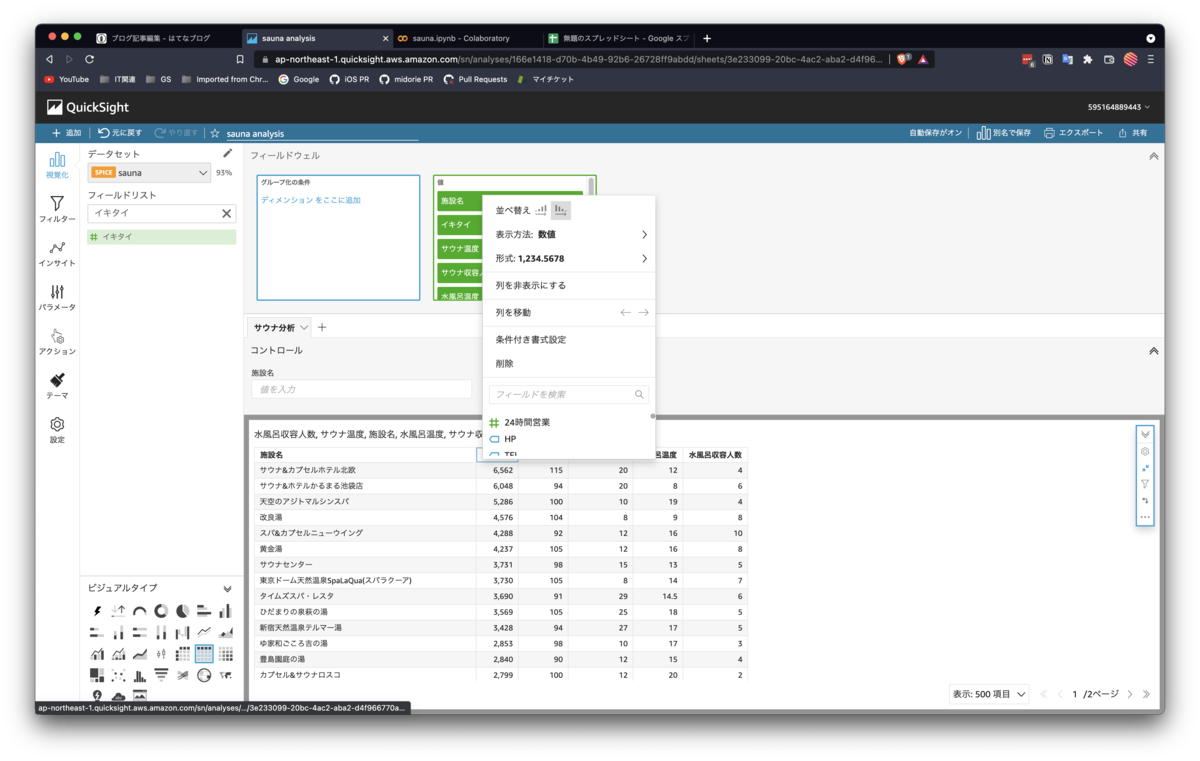
また、可視化対象をフィルターする機能も便利なので、少し紹介させてください。 フィルターは少し複雑ですが、慣れれば色々と柔軟に行えて便利な機能です。 今回は、上記で作成した図を、施設名で絞り込んでみたいと思います。 手順は3つあります。
4.1. パラメータ作成
まずはパラメータを作成します。パラメータには、検索対象のフィールドを指定します。適当な名前をつけ、↓のように設定して作成しておきます。

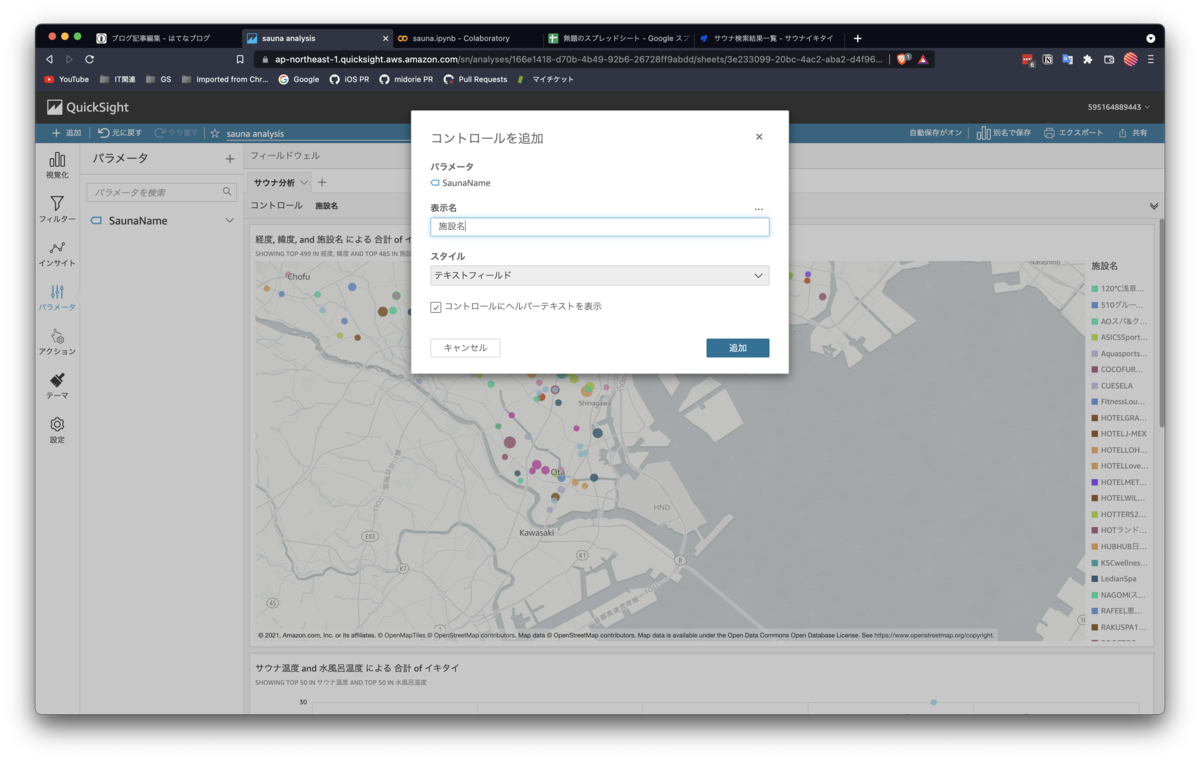
4.2. コントロールの追加
パラメータが作成されると上記のような画面が出るので、コントロールの追加をおこないます。これにより、フィルタ時に利用するコンポーネントを追加できます。
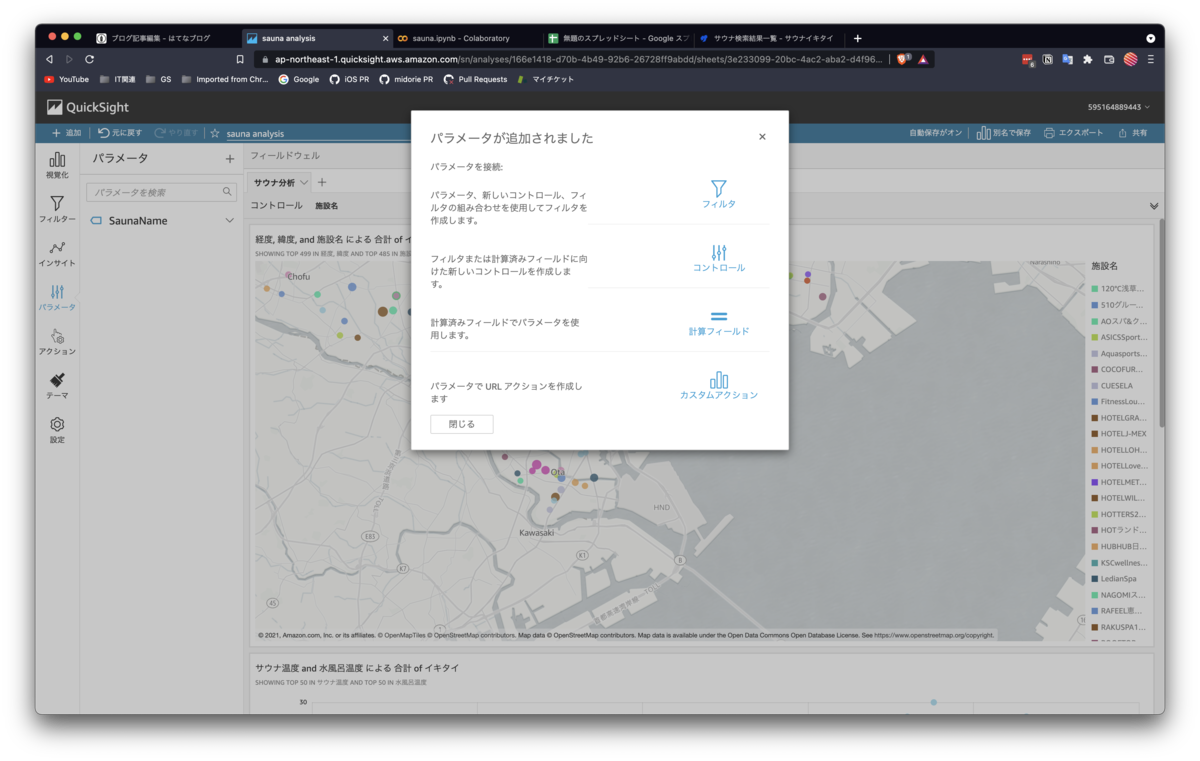
4.3. フィルタの作成
最後にフィルタの作成を行います。今回は施設名で絞りたいので、フィルタするフィールドに、「施設名」を選択します。
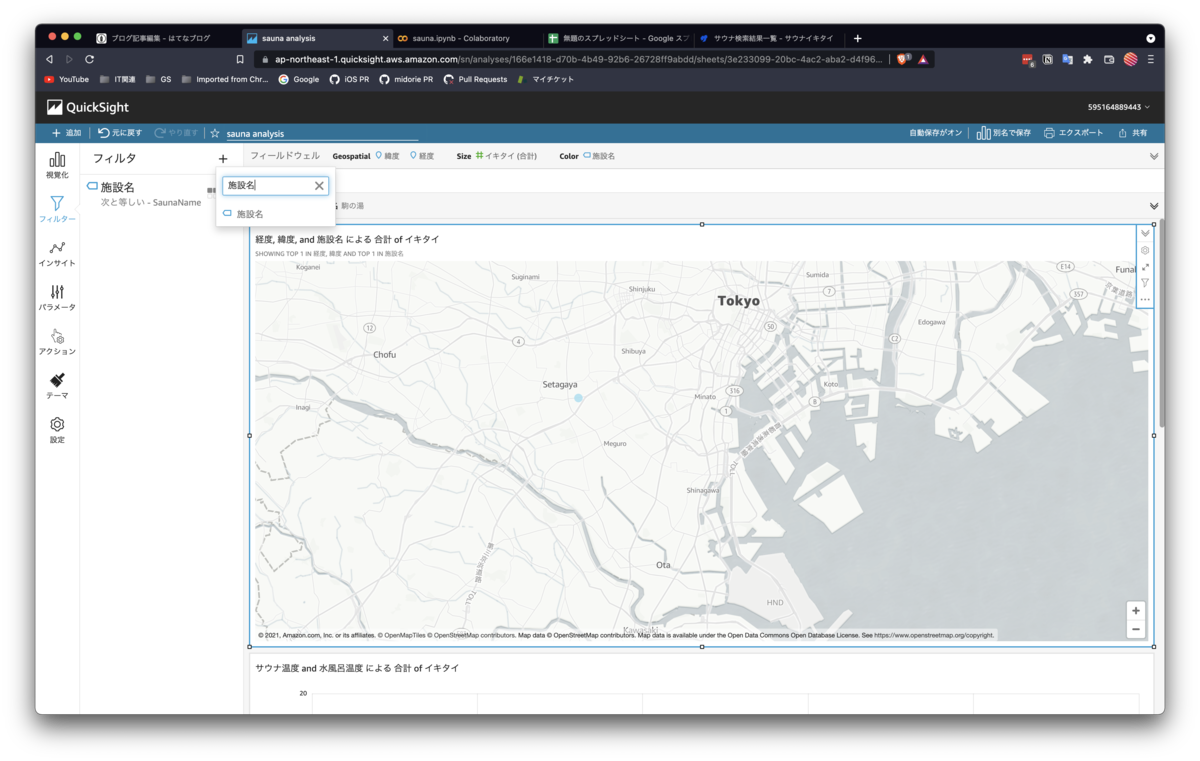
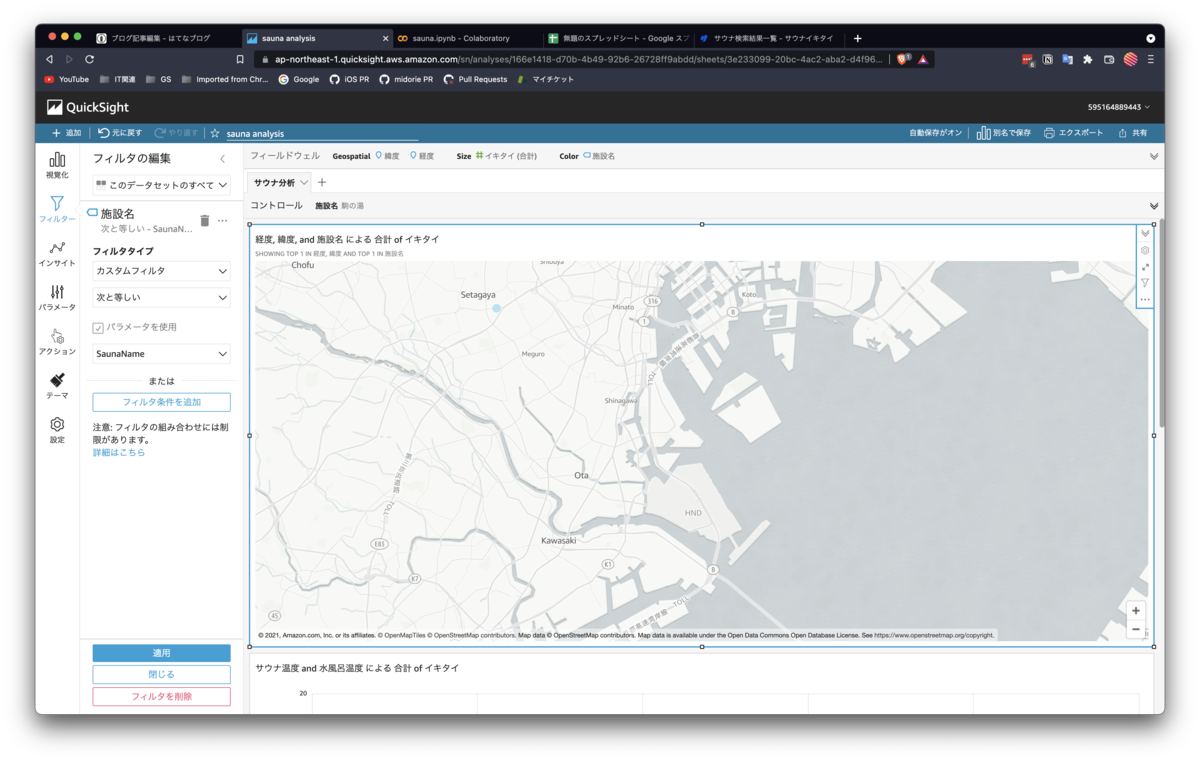
少し複雑でしたが、設定は以上です。実際にフィルターを使ってみます。先程作成したテキストフィールドから、試しにわたしのホームサウナである「駒の湯」と入力すると、ダッシュボード内の図が、すべて駒の湯だけに絞り込まれました。

まとめ
今回は、サウナイキタイのデータをスクレイピングして収集し、QuickSightを使って可視化してみました。QuickSightを使ってみた所感としては、正直慣れるまでかなり使いづらかったです… ただ、個人的に地図上マッピングは感動しましたし、フィルター機能も使いこなせば色々なことができそうな気はしています。今回の調査を踏まえて、ダッシュボードを作って社内に公開することで、社内のメンバーなら誰でもGreenSnap内のデータ分析ができるようなダッシュボードを作っていけたらなと思います。この記事が、これからQuickSightを使おうか悩まれている方、そしてサウナが大好きな方の参考になりましたら幸いです。笑
最後に
弊社では絶賛エンジニア募集中です。BtoCのサービス開発をしてみたい方や、植物に興味のある方は是非応募してください。 カジュアルに話だけでも聞きたいという方もお待ちしてます。 www.wantedly.com